
最近由于各种事情,导致有一段时间没有写博客了,我深知养成一个好的写作习惯是非常不容易的,所以心里也一直惦记着写博客这个事情,趁着这两天闲下来了,又可以愉快地写作了,开心😁
这次准备写一篇比较有“深度”的文章,准备从v8引擎的角度去讲解我们写的js代码是如何被执行的,从而能让我们对js的运行原理有一个更深刻的认识,废话不多说,开始吧!

破局者 👉 Chrome
在上古时期,ie在与网景浏览器的大战中胜出之后,便一直霸占着浏览器的市场,但由于其孱弱的性能以及各种层出不穷的问题,让开发者与用户都有很大的怨言
那一段时期对于前端开发者来说无疑是黑暗的,虽然我自己没有亲身经历过,但是从网上或多或少也有所了解。那段时期的前端开发岗位极其不受重视,甚至被戏称为“切图仔”,真的是处于开发鄙视链的最底层,在那段最难的时光里,一个伟大的破局者正在逐渐走来,那便是 Chrome
在2008年9月2日,第一版的chrome正式发布了,它的出现迅速打破了ie的垄断,并逐渐占据了市场的份额,到目前为止,虽然市面上的浏览器种类非常多,如opera、firefox、chrome、safari,ie,但是chrome的市场份额依旧达到百分之70以上,chrome凭借它强大的实力碾压了那个遭人唾弃的ie,同时也给前端开发领域带来了春天,而这一切在很大程度上依赖于Chrome的核心黑科技,那便是 v8引擎
神奇的V8引擎
v8引擎其实就是一个js引擎,用于解析执行js代码,它属于浏览器内核的一部分,而内核的另一部分则是gui渲染引擎,它是用于响应用户操作和更新界面的。它俩是一个互斥的关系,也就是说一个引擎工作,那么另一个引擎就会被挂起而无法工作,这也就是为什么我们在开发时常说要避免耗时过多的js同步任务,因为这会导致界面停止响应,从而毁掉用户的体验
不同浏览器有不同的浏览器内核,具体对应如下
- IE、傲游、世界之窗浏览器、Avant、腾讯TT、Sleipnir、GOSURF、GreenBrowser、KKman:Trident
- Mozilla Firefox、Mozilla SeaMonkey、waterfox(Firefox的64位开源版)、Iceweasel、Epiphany(早期版本)、Flock(早期版本)、K-Meleon:Gecko
- Opera:Presto(废弃)
- 傲游浏览器3、Apple Safari (Win/Mac/iPhone/iPad)、Symbian手机浏览器、Android 默认浏览器:Webkit
- Chrome、Opera:Blink
可以看到,浏览器内核也是多种多样的,不同内核有不同的解析规范,这就会导致相同的代码在不同浏览器下呈现不同的效果,这也是我们作为前端工程师经常需要处理的一类问题:浏览器兼容性,这在以前的”前端蛮荒时代”是一件非常重要的工作,但是现在随着w3c标准的推进与普及,各家浏览器厂商都在努力跟进标准,这也就表明在不远的将来,浏览器兼容 这个问题也就不需要再考虑了

对于标准化的支持做的最彻底的当属chrome使用的内核: Blink,这也是为什么前端开发工程师喜欢它的原因(省心,高效)。在完美支持标准化的同时,性能也是甩开其他内核一大截,其中重要的一条原因便是使用了Google开发的黑科技:V8引擎,它的性能之强大以至于现在被应用在了很多除开浏览器的场景下,甚至可以说现在前端的百花齐放很大程度上得益于V8引擎的出现,下面解释下为什么我会这么说
前端工程化(webpack,gulp,grunt…)、服务器node中间层、跨端开发框架(uniapp、taro)、桌面端应用开发(electron),现在这些火热的前端前沿技术都离不开nodejs,而nodejs又是一个基于V8引擎的JavaScript运行时,所以可以认为如果没有V8引擎的出现,也许我们现在还是“切图仔”,而不是前端工程师
V8引擎执行js的过程
为什么当初nodejs的创建不使用其他js引擎呢?原因无他,就是强大的性能,那为什么它会有强大的性能呢?这个问题就需要从V8引擎如何执行js的过程开始聊起了,那么先放一张流程图,可以让我们对整个流程有个大致了解
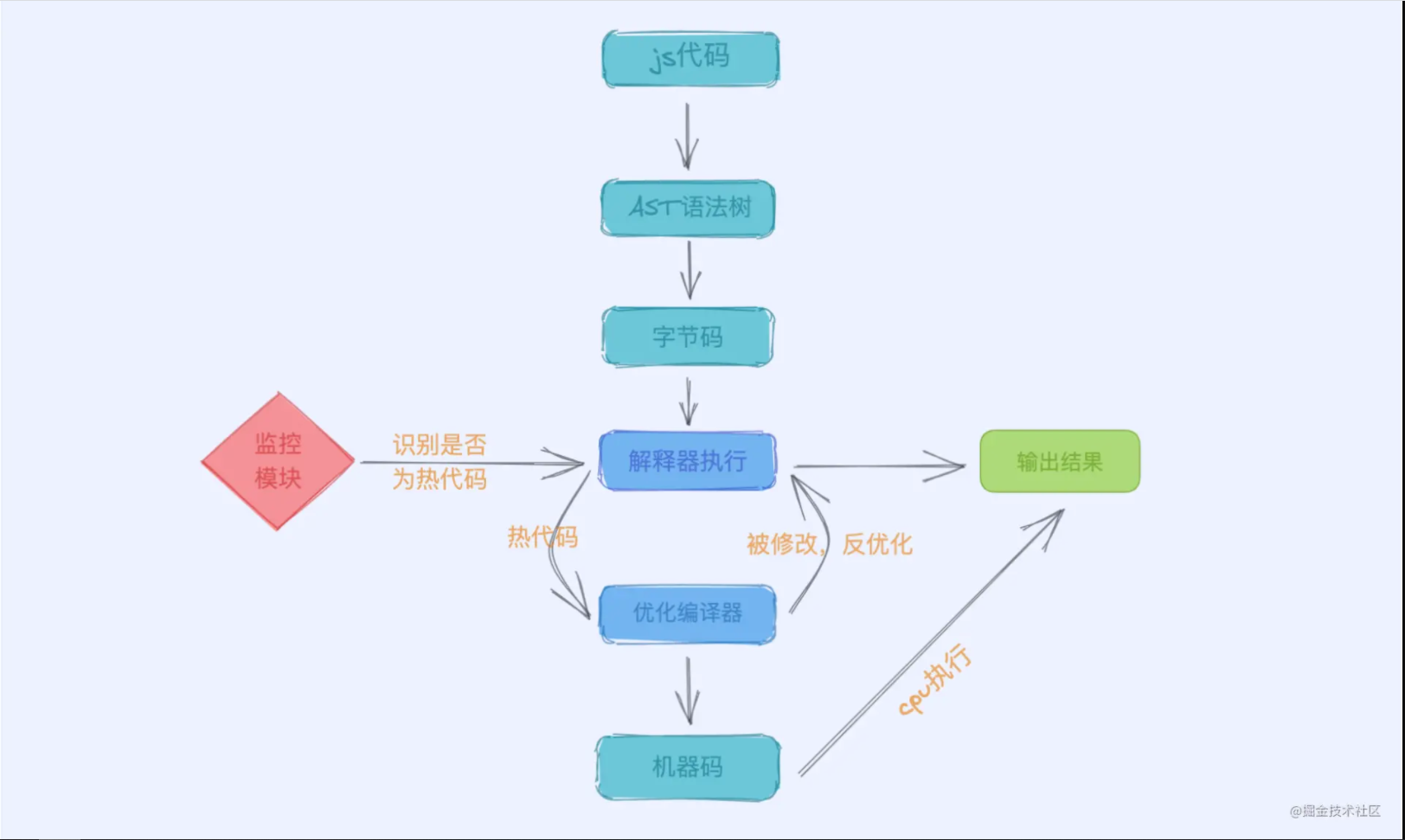
解析阶段
这个阶段里,V8的 解析器(Parser) 会将我们的js源代码转换为AST,对于AST的讲解,可以看我的这篇文章
编译生成字节码阶段
在这个阶段里,会将解析阶段生成的AST通过 解释器(Ignition) 编译为字节码,它作为中间代码会在被执行时编译为机器码
编译生成机器码阶段
在这个阶段里,解释器(Ignition) 会将上一步生成的字节码编译为机器码,从而让cpu识别并执行
V8引擎执行js的方案变化
V8引擎执行js的过程大致可以分为上面三步,但是要想达到强大的性能光有这三板斧可不够,其间是存在一些黑科技来提升性能的,至于有哪些黑科技我想晚一点在聊,因为我想先聊下老版本的V8是如何执行js的😁
在老版本的V8中,其实是不存在 编译生成字节码 这个阶段的,js代码是直接被编译为机器码的,这也就是为什么说V8引擎的性能极其强大的原因了,机器码是cpu唯一认识的代码,在执行时由于不需要编译,所以执行效率会非常高。既然如此完美,为什么现在会加上编译成字节码这一步呢?这不是多此一举吗?接下来就聊聊其中的原因吧~

js直接编译为机器码所需要的时间相对于字节码来说是更长的,如果js源码很大,那么所需的时间肯定是不可接受的。那么,如何解决这个问题呢?缓存,这个万金油的解决方案在这里也是适用的,早期的V8引擎会将编译出来的机器码缓存下来,缓存的方式分两种:
- 浏览器未关闭时候,直接存储到浏览器本地的内存中
- 浏览器关闭了,直接存储在磁盘上
这样我们在浏览同一个网页时V8引擎就可以跳过js的编译阶段,直接执行缓存下来的机器码,从而大大提高了网页性能。看似很完美了,但是这种方案是存在问题的,存储下来的机器码所占用的空间可能是js源码的几百甚至几千倍,这就导致占用了大量的内存和硬盘空间,从而导致chrome的内存占用极度飙升,最终导致浏览器应用崩溃,所以这种方案也不完美
如何去优化缓存机器码这个方案呢?V8引入了 惰性编译 的方案,具体来说,就是在es6之前,只存在全局和函数作用域,V8只会缓存全局作用域中的代码,而函数作用域的代码只有在被调用时才去编译,并且也不会缓存其编译后的机器码,这样的优化既保留了缓存带来的受益,又可以保证缓存大小在一个可控的范围内,nice~

真的已经是完美方案了吗?肯定也不是的,在 ES6 和 Vue、React 等这些没有普及之前,绝大部分开发者都使用的是jQuery,以及RequireJS等类似产品,JQ插件各种引用,各种插件或者开发者自己封装的方法,为了不污染其他使用者的变量,一般都封装成一个函数,这样问题就来了,惰性编译不会保存函数编译后的机器码,如果一个插件太大那等到使用函数再去编译,编译的时间上就会变得很慢,甚至达到一个不可接受的程度,哎,真的一波三折,看来利用机器码缓存的这一条路应该是走不通了,那么就只能引入字节码了~
字节码其实是机器码的抽象,它所占用的内存比机器码小很多很多,这也就解决了缓存机器码时占用空间过大的问题,但在执行时就需要先将字节码转为机器码之后才能真正被执行。虽然执行速度上比不上直接执行机器码,但是还是在可接受的范围内的,同时还大大减小了内存与硬盘的占用,相较之下,加入并缓存字节码这种方案是更优的,这种方式也一直被沿用至今
优化黑科技
上文提到了V8引擎中加入了许多黑科技来提升性能,这一节就来聊聊它们的其中之一:TurboFan(优化编译器)
在我们所写的代码中,是会存在多次被调用的代码片段的,同时V8里有专门的监控模块,它会将多次被调用的代码片段标记为 热代码,而热代码会被 TurboFan(优化编译器) 用来做优化工作,优化原理其实很简单,我们接着聊
热代码既然会被多次调用,那么每一次的调用都会走一遍从字节码编译成机器码的流程,因此会耗费很多时间在这上面,如果能把热代码对应的机器码缓存下来,那么不就可以每次调用热代码时直接执行机器码了吗?这也就是 TurboFan(优化编译器) 所做的优化,由于热代码不会大量存在,所以缓存机器码的大小是可接受的并且大大减少了执行时编译字节码的时间
这个优化方案其实还存在一个问题,由于js是动态语言,对象的结构和属性在运行时是可以发生改变的,一旦发生改变,对应的热代码的缓存是不可用的。这个问题V8也考虑到了,同样使用 TurboFan(优化编译器) 来解决,术语是 反优化,具体来说它会将失效的热代码回退到AST,并取消热代码的标记,然后重新通过解释器编译生成字节码,如果此段代码再次被标记为热代码,则会重复热代码优化的步骤
其实V8的优化黑科技还有很多,例如内联缓存、隐藏类、快属性、慢属性等,这些只有以后有时间再来慢慢研究了😂
结语
通过学习研究V8引擎,收获了很多以前不了解的知识,这些“底层知识”虽然不会直接对我的工作产生效益,但我知道这些知识都是长线投资,要想在前端的道路上走得稳,走得远,这些“底层知识”是必须掌握的,我也会不断去钻研这些知识,因为我知道 路漫漫其修远兮,吾将上下而求索
